En automatiseret online pengemaskine
Gæsteindlæg skrevet af Casper Schneidereit for 1 decade siden | Se alle indlægI dette indlæg får du en komplet opskrift på en automatiseret online pengemaskine. Lyder det ikke bare godt :-)? Jeg vil gennemgå de forskellige elementer og processor, der er i opbygningen af en fuldautomatiseret pengemaskine. Indtægterne kommer via salg fra affiliate marketing.
I grove træk handler det om at finde en niche med begrænset konkurrence, og om bygge en affiliate side omkring denne niche. Der er flere gode eBøger, som beskriver værktøjer og metoder til at finde attraktive nicher, så det gider jeg ikke komme ind på her. I resten af indlægget vil jeg tage udgangspunkt i, at nichen er fundet og nu skal den omsættes til en pengemaskine.
Først og fremmest skal hele processen med at opdaterer priser, oprette og slette produkter automatiseres. Vores tid er for kostbar til manuelt arbejde (det er en automatiseret pengemaskine vi bygger, ikke bage en pengemaskine).
Der er forskellige metoder til at automatiserer dette, lad os lidt på dem her:
XML feeds
En række webshops tilbyder XML feeds med produktdata. Det er som sådan godt nok, men alle andre har også adgang til disse data, og alene det kan gøre konkurrencen større. Jo lettere det er, jo flere er der plads til.
Ud over det, så er det dumt at lade sig begrænse på grund af, at en webshop ikke kan leverer et XML feed. Vi skal ikke passivt vente på, at de giver os data, vi skal aktivt ud og hente data.
Fordelen ved XML feed er, at data kommer på en struktureret måde, som er dokumenteret. Vi ved med med andre ord, hvordan data vil blive leveret.
HTML grabber
En HTML grabber er en applikation, der aktivt tager data fra et website og giver os det i det ønskede format. Det er mere kompliceret end bare at loade et XML feed ind, og der skal også laves noget unik programmering for hver webshop.
Men lad os i første omgang kigge på, hvordan en HTML grabber kan laves:
Det handler om at analyserer webshoppes HTML kode og lede efter en skematisk opbygning. HTML opbygningen for en produktside kan se sådan her ud (lidt simplificeret):
- Alle produkter ligger i div-tagget med id produkter
- Hvert produkt ligger i et div-tag med class produkt
- Under hvert produkt er der span med class henholdvis pris og navn, som indeholder de ønskede oplysninger.
Vi kan også tage et autentisk eksempel. På produktsiden ved ShopWithSocks.com for sokker i størrelse 44. (http://danmark.shopwithsocks.com/44/) kan vi konstaterer følgende:

- Hvert produkt ligger i et div-tag med class produkt
- Prisen ligger i div-tag med class info
Det autentiske eksempel indeholder selvfølgelig en masse koder, som vi ikke skal bruge til noget. Men når vi kender den skematiske opbygning, kan vi via Regular Expressions og forskellige PHP funktioner skære alt kode fra, og ender med et arraya> med de ønskede data. Funktionen explodea> er i øvrigt meget nyttig til denne øvelse.
Lidt erfaringsdeling omkring HTML grabber
Det er værd at bemærke, at mange webshopsystemer danner forskellige HTML koder. Hvis varen er på tilbud, man kan spare X procent på varen, eller der er tilknyttet en førpris til varen. Det skal HTML grabberen
naturligvis tage højde for. Vær´ derfor grundig når du går webshoppens HTML kode igennem og prøv at finde alle de forskellige HTML output, som webshoppen kan finde på at danne.
Den skarpe læser har sikkert bemærket problematiken med overstående model. Hvis webshoppen får nyt system, skal der programmeres nye grabber. Og ja, sådan er det - men det sker heldigvis relativt sjældent.
CSV fil og cronjob
Jeg plejer at lade mine HTML grabber skrive outputtet til en kommasepereret fil (CSV fil). Dette er opsat som et cronjob, der køre en gang i døgnet. Hvis HTML grabberen fejler,
eller leverer data, som jeg ikke forventede, modtager jeg en mail. Nu laver jeg det selv, men alt det her kunne lige så godt være sat op og løst af din indiske programmør, der sørger for at holde dine HTML grabbere vedlige.
Hvis en HTML grabber fejler, skal den naturligvis ikke overskrive CSV filen. Affiliate siden vil stadigvæk fungere, men med data der er mere end 24 timer gammelt. I langt de fleste tilfælde er det ikke noget problem, da priserne ikke ændre sig fra dag til dag.
Data automatiseringen er på plads
Kombinationen af en HTML grabber samt en billig/stabil programmør til at holde den vedlige, giver en fuldstændig automatiseret process i forhold til at holde affiliate siden up to date med data for webshoppen.
Det største problem er løst i automatiseringen. Det er en kæmpe fordel, da du blot kan skalerer overstående op til 10, 20 eller 50 sider.
Indhold
Det næste step i opbygningen af siden er at lave noget indhold i form af tekst. I forbindelse med den seneste Google Panda-update er kvaliteten af teksten i endnu højere grad vigtig. Du kan vælge at lave det selv,
eller outsource det til en dygtig tekstforfatter. Personligt kan jeg godt lide at brugeren, ikke bare mødes af den klassiske "tekstmur". Her er et par eksempler på hvordan det statiske indhold kan se ud:

Denne side er ikke opbygget omkring HTML grabber modellen. Det er mere den statiske artikel, der er flot opsat og giver rigtig meget godt indhold til brugeren. Det tager længere tid at lave dette, men på sigt er tiden
tjent ind igen, da det er nemmere at lave effektiv linkbuilding til sådan en side.

Denne side er opbygget med HTML grabber modellen. Her har jeg valgt en lang artikel øverst og produkterne nederst (siden henter produkter fra to webshops, dvs. der er to HTML grabbere tilknyttet). I kan se selve "produktområdet" på siden her:
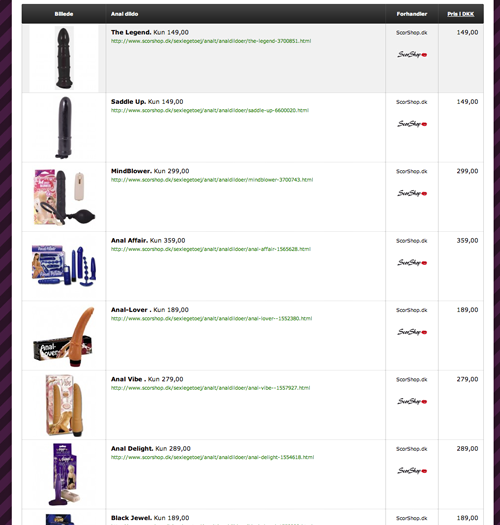
Summeret op er der selvfølgelig noget arbejde i at skabe denne artikel. Men nu har du en færdig side, som der er klar til at blive linkbuildet op i Google. På meget små nicher og konkurrencefattige nicher behøves der ikke mere content. Men det kan være en fordel at tilknytte en blog og få en ekstern skribent til at ligge nye artikler på i ny og næ.
Har du været heldig, og gjort det rigtigt, så kan selv 15 besøgende fra Google være nok til siden giver 400 kr om måneden. Når du først har linkbuildet siden til tops, kræves der lidt løbende linkbuilding, som naturlivis også kan outsources.
Efter noget tid skulle du gerne stå tilbage med er en side, der giver dig en løbende indtægt, og kræver minimal vedligeholdelse.
At skalerer det op
Her er en illustration af hvordan det kan se ud, hvis det skaleres op:
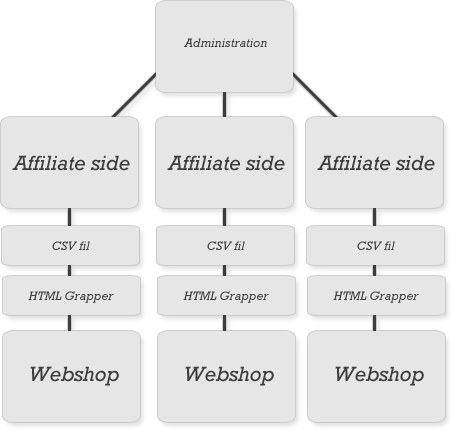
For at spare tid bør dit system bygges op omkring èt administrationssystem. Et godt tip er at få bygget et centralt blogsystem også. Du kan give eksterne tekstforfattere adgang til, så de løbende kan ligge nye indlæg op.
Potentiale og tidsforbrug
For at skabe en ny side kunne tidsforbruget se sådan her ud:
Research : 1 time.
HTML grabber : 2,5 time.
Indhold : 4 time.
Eller cirka 8 timer i alt, for at skabe en ny potentiel pengemaskine. Bruger du så 4 timer om dagen på linkbuilding af alle dine sider, så kan du realistisk set opbygge 150 sider på et år.
Hvis bare 100 af dem når en indtjening på 400 kr./mnd., så har du indtægt på 480.000 kr om året.
Det kræver tid og vilje. Forvent at nogle sider bliver fiaskoer. Forvent at Google løbende vil komme op, med nye algoritme opdateringer.
Hvad gør jeg selv
Personligt er jeg faktisk ved at gå væk fra denne metode til at skabe penge på nettet. Jeg satser i højere grad på nyttige kvalitetstjenester. Det synes jeg sjovere at arbejde med, men hvis du bare fokuserer på en løbende indtægt hver
måned, så kan overstående model fungerer lige så godt.
Det kan endda blive en rigtig godt forretning, hvis du gider bruge tiden på det.
|
Har du lyst til at hjælpe os? Kunne du lide indlægget, så ville vi blive oprigtig glad, hvis du delte dette indlæg med dit netværk.
|
» Se andre indlæg her.
Kommentarer til indlæg
Sjovt sammenfald. Jeg har netop selv lanceret en crawler/grabber i dag, som henter udvalgte data fra Trustpilot. Metoden jeg benytter minder meget om den, du beskriver her i dit indlæg.
Hej Casper,
Interessant løsning! Jeg kan godt se det sparer meget tid til eftertjek af kampagner. Hvordan foregår præsentationen af xml dataen helt konkret? Bruges der php til at hente data fra databasen og så præsentere det i html? Jeg legede lidt med en løsning som hedder Datafeedr (http://www.datafeedr.com/), men var ikke helt tilfreds med prisen og brugervenligheden. Hvor meget tror du det koster at få fremstillet noget lignende hos en outsourcet programmør?
Endelig en der forstår fordelen i at automatisere!
Jeg prøver også at automatisere så meget som overhovedet muligt. Et site som http://www.billig-ps3.dk er også 100% fuldautomatisk. Jeg skriver meget lidt tekst engang i mellem.
Et tip til andre er at man godt kan bygge et automatiseret netværk op i wordpress. Det spare mange af de første udviklingstimer. Det skal siges at jeg sagtens selv kan programmere, men ser store fordele i wordpress, da det er nemt at udvikle til.
Erik @ XML data kan ligges ind i databasen, eller bare downloades til serveren som en fil. Det første er nok at foretrække. Angående pris, så tør jeg slet ikke gætte på det :-).
Dennis @ Jeg har ingen erfaring med Wordpress, men fedt hvis det kan overføres mere eller mindre direkte dertil. I princippet er det jo heller ikke et spørgsmål om system / teknik, men mere en fokusering på at få fjernet manuelle arbejdsgange. Det gør stordrift meget nemmere. Der er ikke noget ved at hente 400 kr / mnd på et site der kræver 4 timers vedligeholdelse :-)
Hej Casper.
Rigtig godt og spændende indlæg! Jeg mangler dog en meget væsentlig ting i denne: Jeg er total n00b inden for affiliate markedsføring og er derfor noget i tvivl om hvordan du kobler dine links sammen med affiliate netværk? Jeg har tjekket dine kode og kan ikke umiddelbart se noget om, hvordan det foregår, samt hvilke partnere du bruger. Er det noget du vil bruge et par minutter på at besvare?
Flemming @ÃÂ Tak. Jeg bruger netværkets deeplink mulighed, hvor du har affiliate url+deep url (det er noget netværket skal understøtte). Så først bliver sporings cookie sat, og brugeren bliver efter sendt til deep url. Nu ved jeg ikke hvilke sider du har tjekket kode på, for jeg gør det lidt forskelligt fra websted til websted :-).
Hej Flemming,
Casper kommer sikkert selv med et svar, men her får du alligvel ét.
HTMLgrabberne crawler også produktURLen, altså den præcise sti til netop produktet hos annoncøren. Denne URL kobles så sammen med affiliatenetværkets deeplink struktur og så er du faktisk kørende.
Hej Casper,
Tak for et fedt indlæg. Jeg sidder selv og roder med XML dokumenter, og en HTML grabber er helt sikkert næste skridt herfra.
Jeg er blot nysgerrig efter om du har lavet en side til at crawle en webshop for produkter, eller om du specifikt giver de URLS din HTML grabber skal besøge?
Hej Casper
Meget fint indlæg - har selv tænkt de samme tanker omkring automatisering. I forhold til at crawle andre sites kunne det måske også være interessant at kigge på Yahoo"s YQL Console, hvor man kan udvælge html elementer fra diverse websites og få dem retur i XML eller JSON format - http://developer.yahoo.com/yql/console/
/Jan
Heine @ Jeg plejer at crawle kategori sider f.eks http://www.petdreams.dk/katteartikler/toiletter-og-grus.html -> til http://www.kattebakker.dk . Men du kan også bygge det så du crawler alt på webshoppen. Det kommer lidt an på din strategi med dine data :-)
Jan Skovgaard @ Det vil jeg prøve at kigge på. Tak for linket.
Hej Casper
Spørger du nogen om lov når du grabber deres tekster og billeder? Selvfølgelig er det til webshoppens fordel men webshoppen har jo stadig copyright, ik?
/Lars
Jeg grabber titel, og følger ellers de opsatte rammer for affiliate programmet. Hvis et eller andet projekt strider i mod de rammer, så spørger jeg selvfølgelig om lov :-). Produkttekster grabber jeg som regel ikke.
Yderst interessant indlæg Casper. Jeg finder det ret så spændende at man på denne måde kan mere eller mindre automatisere et site, og hele tiden sørge for at de produkter man sælger er up-to-date.
Men kan disse 1-sides-sites godt ranke i Google, og derved give noget afkast som er værd at bruge tid på? Det afhænger selvfølgelig af hvilken niche man finder, og hvor meget linkbuilding man lægger i det. Og som du siger så skal der ikke mange sites som omsætter for 400 om måneden til, før det kan blive lidt sjovt.
Kim @ Er konkurrencen svag nok, kan en stærk linkprofil omkring en god guide være nok. Men som du sikkert selv ved er der meget der spiller ind. Så en blog ligende funktion, der kan skabe flere sider er ikke nogen dum ide. Specielt ikke da det gør det meget nemmere at målrette mod long tail søgninger.
Søren @ Selv tak ;-)
Nu har jeg en niche side hvor jeg opdatere 30 priser så ofte som muligt, men h**d da k**t det tager tid :S Vil helt sikkert kigge nærmere på HTML grabberen. Så kan jeg også få flere produkt sammenligninger ind på siden. :) Super indlæg!